

Tokenomics #1: The Pricing Evolution of AI Coding Agents
The price of code is eternal vigilance.

Happy (Tokenomics) Tuesday!
Back in 2023, I wrote a post called The Price is AI-ght about how early AI-native startups were starting to wrestle with pricing and how seat-based models were already starting to crack under the weight of unpredictable usage. Since then, the market hasn’t exactly stabilized, but rather has progressed at a rapid rate.
We’ve seen companies experiment with everything from flat rates to token caps, credit systems, and abstracted compute units. Some of the early bets have broken down in public while others are still figuring out how to align real costs with perceived value.
Tokenomics is my attempt to unpack that. It’s a running study on how AI companies make money, where the cost centers really are, and what kind of business models will actually scale.
Things are still in flux, but asking the right questions early matters. If you're a founder building in this world, I hope this is helpful to you!
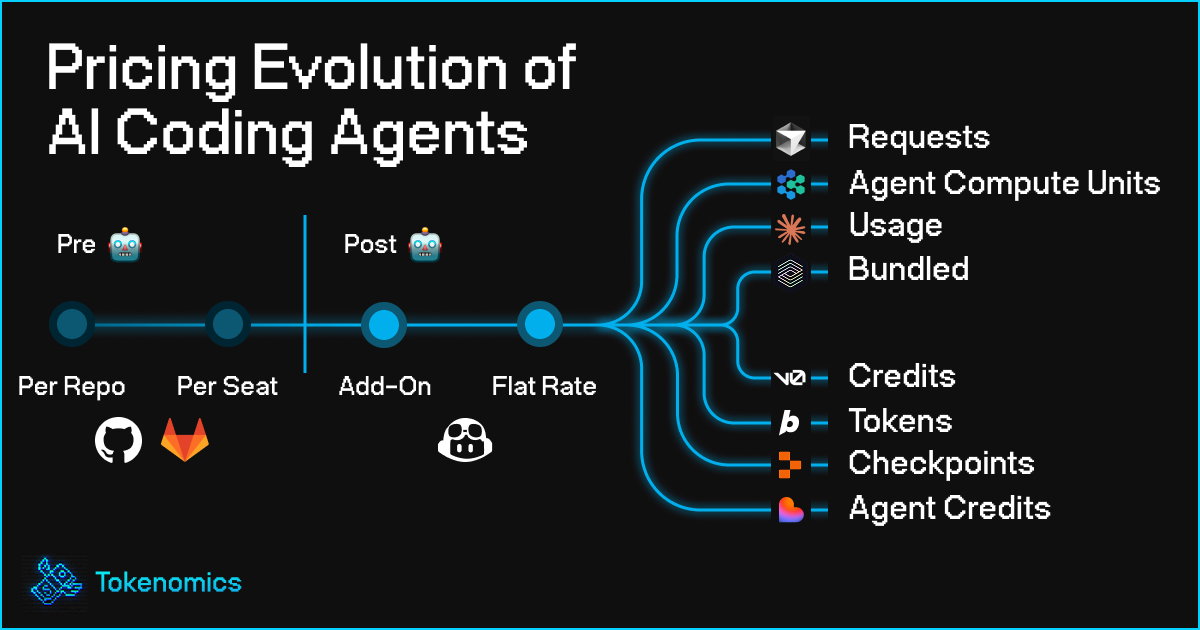
The Pricing Evolution of AI Coding Agents: From Per-Repo to Compute Units
Pricing in the AI world is still early and unsettled. There are a lot of variables in play: how customers use the product, how often they interact with it, what agents are doing in the background, and what the underlying model providers are charging. Most founders I talk to are still figuring out how to balance predictable revenue with unpredictable costs.
This week, I'm diving deeper into how developer tools have evolved their pricing models over the years, why Cursor's recent pricing change stirred up so much controversy, and what the rise of agent swarms means for the future of devtool economics.
To understand where we're headed, I've taken a look the current pricing strategies of some of the major AI coding tools: Cursor, Devin, Claude Code, v0, Bolt, Codex, Replit, and Lovable.
Each model tells a story about token economics, market positioning, and the search for sustainable AI pricing.
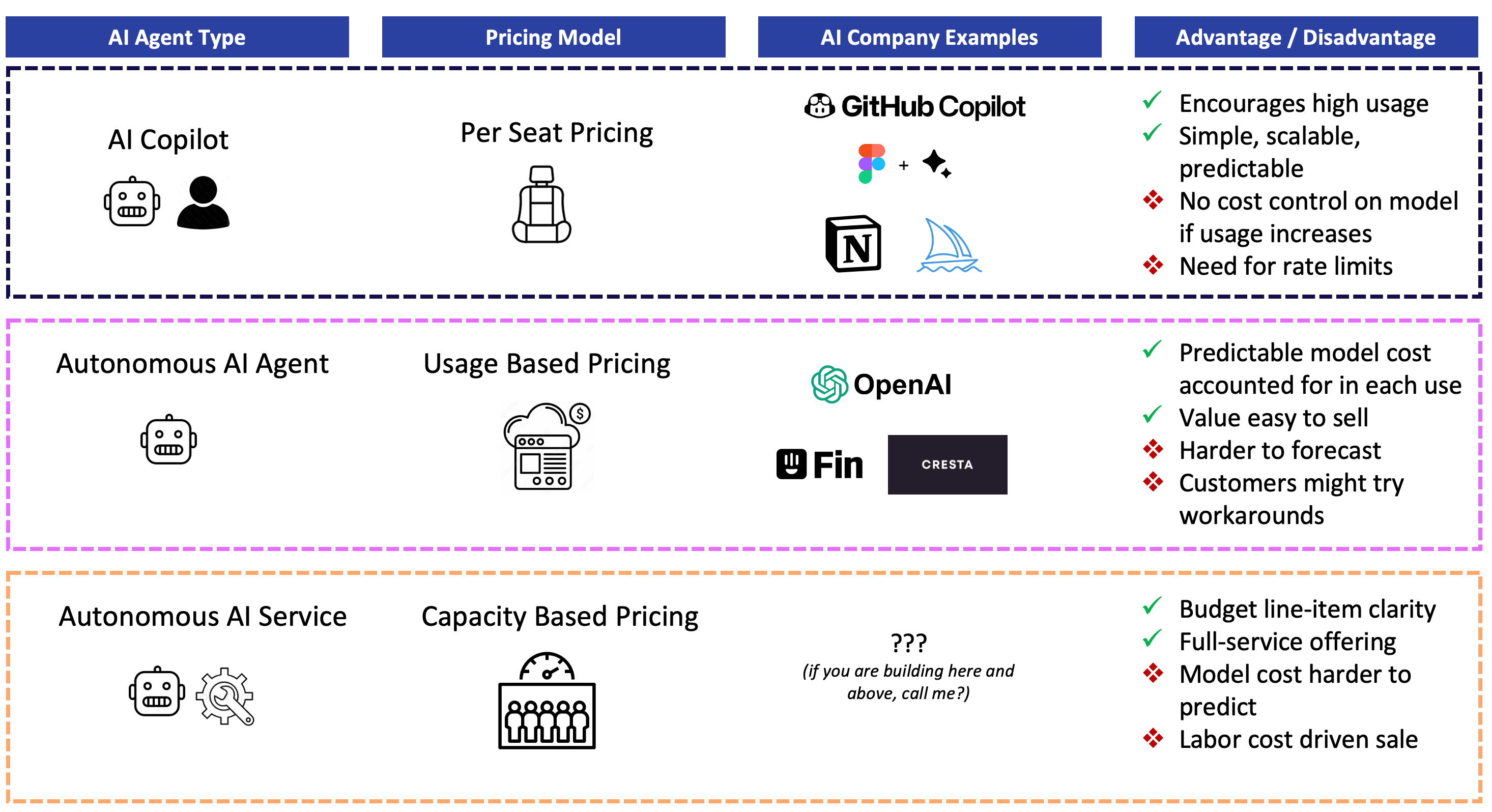
Five Phases of Developer Tool Pricing
Phase 1: Per-Repository Era (2008-2014)
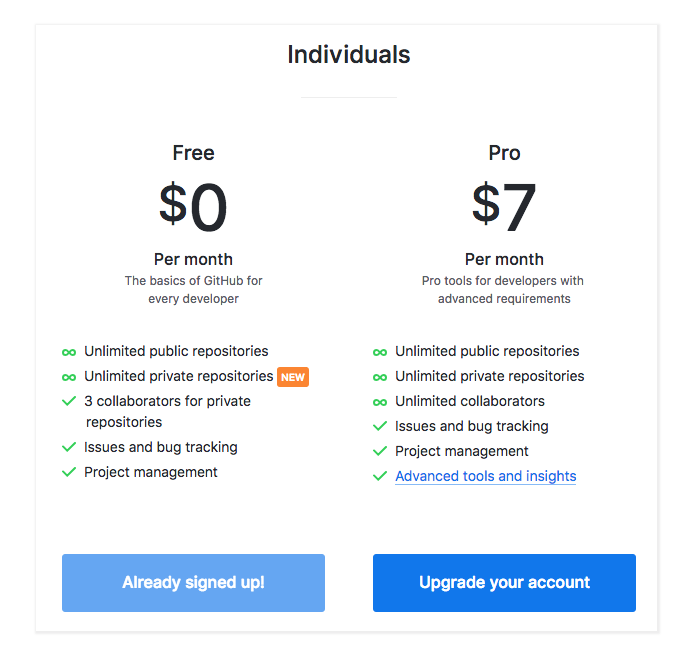
First, a quick turn back in time: GitHub started simple in 2008 with a freemium model based on private repositories. Public repos were free, and you paid for privacy. In 2011, a "Micro" plan cost $7/month for 5 private repos, while a "Medium" plan ran $12 for 10. GitLab followed a similar model, focusing on features gated by tiers rather than user count.
Why it worked: Developers often worked solo or in small teams. Metering access to private code, not people, aligned with real usage patterns of the time.
Phase 2: Per-Seat Enterprise (2015-2020)
As usage shifted from solo developers to teams, both GitHub and GitLab introduced per-seat pricing. GitHub Team and GitHub Enterprise charged $4–$21 per user/month depending on features. The shift made sense: collaboration became the primary value driver, and per-seat pricing mapped cleanly to team structure and enterprise budgets.
Why the shift: Enterprises needed budgeting clarity. As more companies adopted CI/CD and DevOps pipelines, tools scaled across large teams. IT procurement teams preferred clear pricing per developer, and unit economics became more predictable.
This model helped turn devtools into big business. GitHub had around 28 million users when Microsoft acquired it for $7.5 billion in 2018. GitLab went public in 2021 and now serves more than 30 million users with $500M+ ARR. The key thing: pricing was never about compute. It was about developers.

Phase 3: Flat-Fee AI Augmentation (2021-2023)
GitHub Copilot entered in 2021 with a new twist—AI assistance priced at a flat $10/month per user. It didn't matter how much you used it. The value was in seamless integration and predictable cost, abstracting away the complexity of token consumption.
Why it gained traction: Copilot was cheap, worked within VS Code, and offered high perceived ROI for daily coding tasks. Predictability trumped cost control, and developers didn't need to think about usage limits.

Phase 4: Flat-Rate with Usage Caps (2023-2024)
Then came Cursor in 2023.
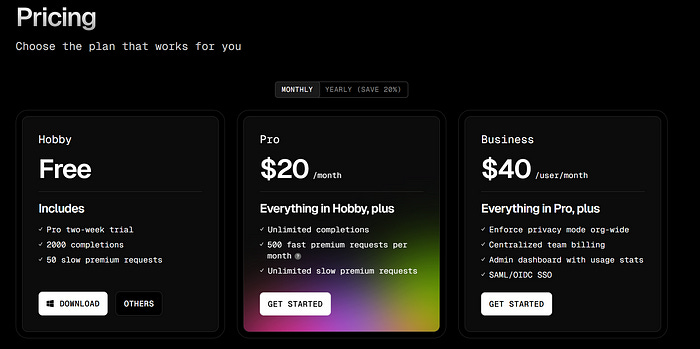
At $20/month for the Pro plan, users got up to 500 "requests" per month; a flat subscription fee with a usage ceiling. This wasn't true usage-based pricing; users didn't pay per token or per API call. Instead, they paid a predictable monthly fee but were capped at an abstract number of "requests."
Why this worked initially: In the early days of AI coding tools, usage patterns were relatively light and predictable. Most requests were simple completions or small code generations. The abstracted limits felt generous, and few users hit their caps.
The Cursor Controversy: When Flat-Rate Pricing Breaks
By June 2025, Cursor's economics had become untenable. As the product matured, power users started chaining together complex multi-step agents, piping in huge context windows, and running long, compute-heavy sessions. What looked like a flat subscription on the surface was burning through API credits underneath.
In the meantime, Cursor continued to experience breakneck growth and saw its annual recurring revenue breach the $500 million mark by June 2025, after revenue doubling roughly every two months.
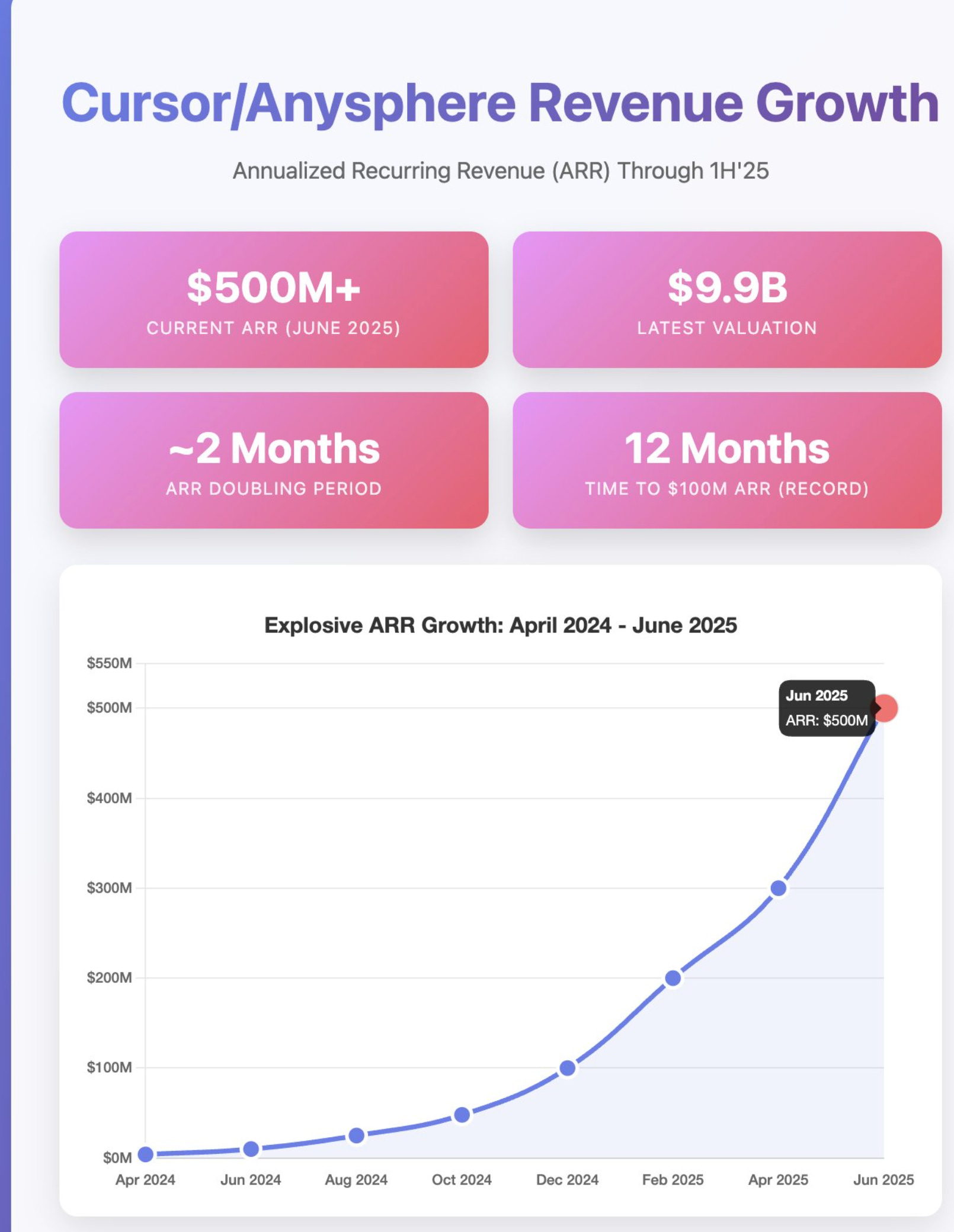
The company was forced to respond. Overnight, it dropped request-based pricing entirely and moved to a hybrid usage-based billing system grounded in token consumption. The new Ultra plan, for heavy users was priced at $200/month and offered ~20x more usage, but the Pro plan introduced hard limits based on compute consumption, not requests.
The backlash was swift. Developers were used to Copilot-style predictability. They didn't expect to face massive overages under a $20 plan. Some users reported bills of over $1,000 in a single month. Cursor was forced to introduce more transparent dashboards, offer refunds, and respond to community criticism.
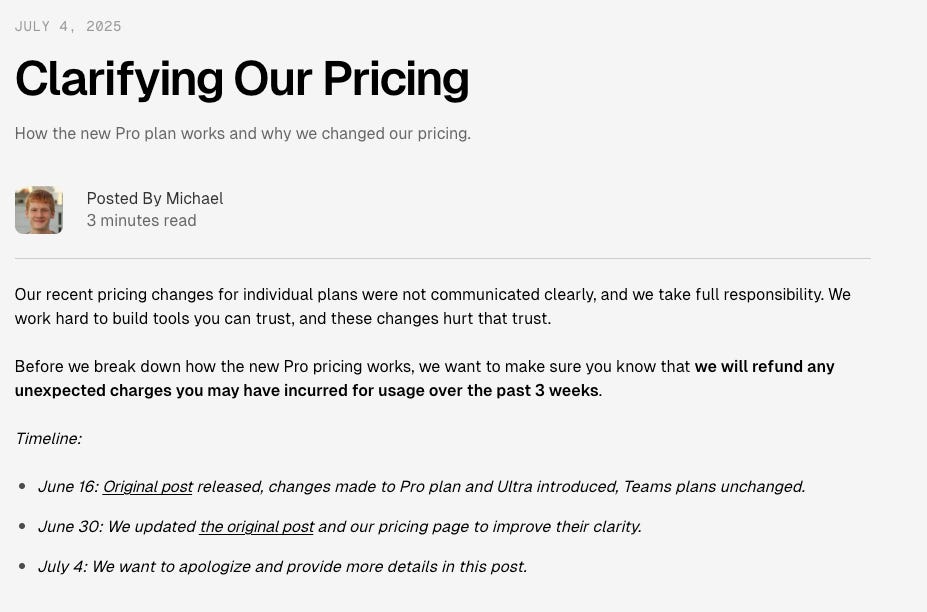
To their credit, the Cursor team responded swiftly and constructively. Within days, they issued public explanations, offered refunds to affected users, launched clearer usage dashboards, and allowed existing annual subscribers to retain the old request-based plan until renewal. They also clarified the new system’s controls, including spending caps and model routing options, to restore trust and transparency.
But what about the others?
Phase 5: Abstracted Usage Units (2024-Present)
The newest evolution attempts to solve the token complexity problem by abstracting usage into more intuitive units that still map to underlying costs. To understand how this plays out in practice, I looked into the other seven leading AI development tools.
Devin: Agent Compute Units
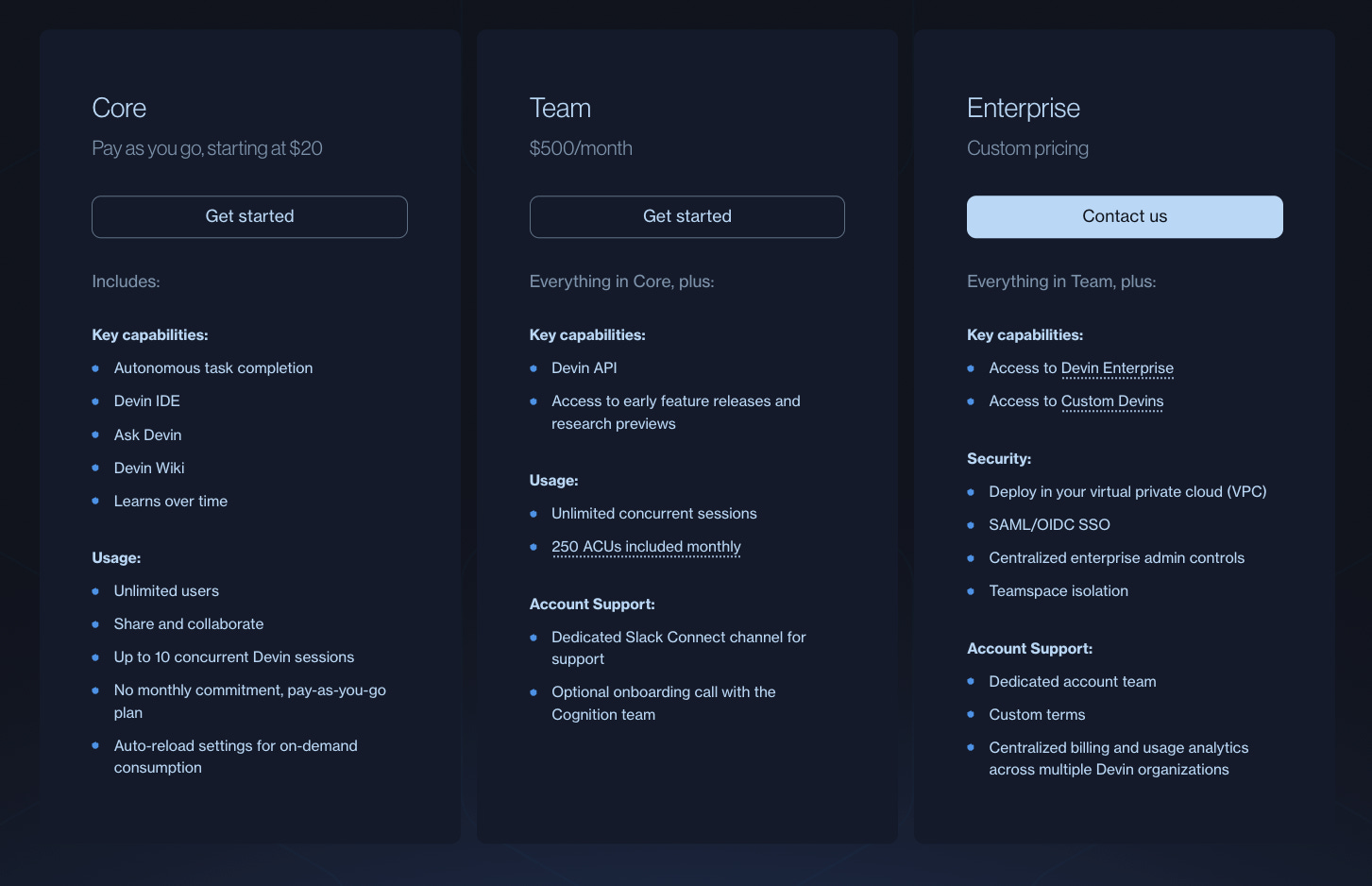
Devin's Agent Compute Unit (ACU) is a normalized measure that bundles together all computational resources (think virtual machine time, model inference, and networking bandwidth) into a single unit representing approximately 15 minutes of active AI development work.
The Core plan charges $2.25 per ACU with pay-as-you-go billing, while the Teams plan includes 250 ACUs at $2.00 each.

As each ACU represents approximately 15 minutes of "active Devin work," the $20 entry plan is equivalent to about 2.25 hours of work.
Which may not seem like much at first glance, but Devin 2.0 now completes over 83% more junior-level development tasks per ACU compared to its predecessor, nearly doubling the output per unit.
Tokenomics Takeaway: Devin has created units that abstract away model complexity while maintaining meaningful cost correlation. Variable task complexity is baked into the unit calculation, making pricing more predictable for users while preserving unit economics.
Claude Code: Tiered Subscription & Model Ownership
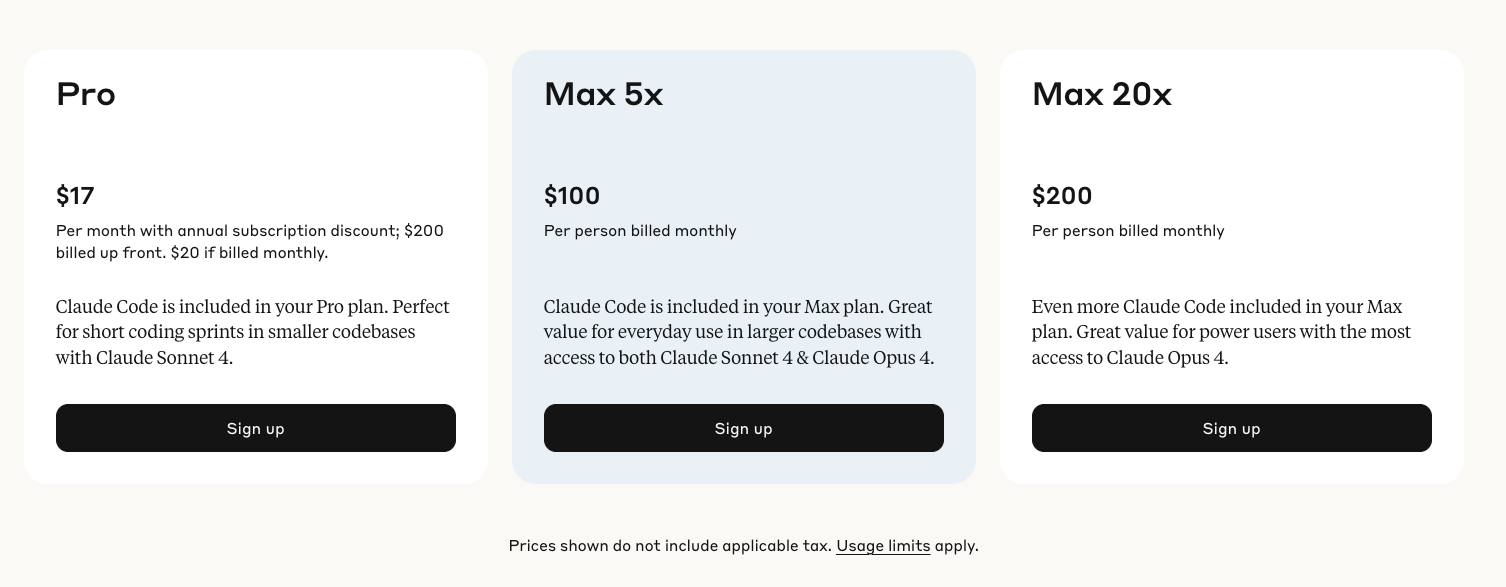
Claude Code operates on a tiered subscription model: Pro ($20/month) provides 10-40 prompts every 5 hours for small repositories, while Max plans offer 5x ($100/month) and 20x ($200/month) usage with 200-800 prompts every 5 hours for larger codebases.
Starting at $17 per month for individual developers, with enterprise plans reaching significantly higher price points, Claude Code has seen 300% active user growth and 5.5x revenue growth since launching Claude 4 models in May.
Pro subscribers can only access Sonnet 4, while Max subscribers can switch between Sonnet and Opus 4 models using the /model command. The platform targets organizations with dedicated AI enablement teams and substantial development operations.
Tokenomics Takeaway: Claude Code's tiered approach works because Anthropic owns the underlying models, giving them a significant cost advantage over competitors paying third-party API fees. While we don't know their exact internal compute costs, this vertical integration likely allows much higher gross margins than tools like Cursor that were paying full API rates.
v0: Mapping Pricing to User Value
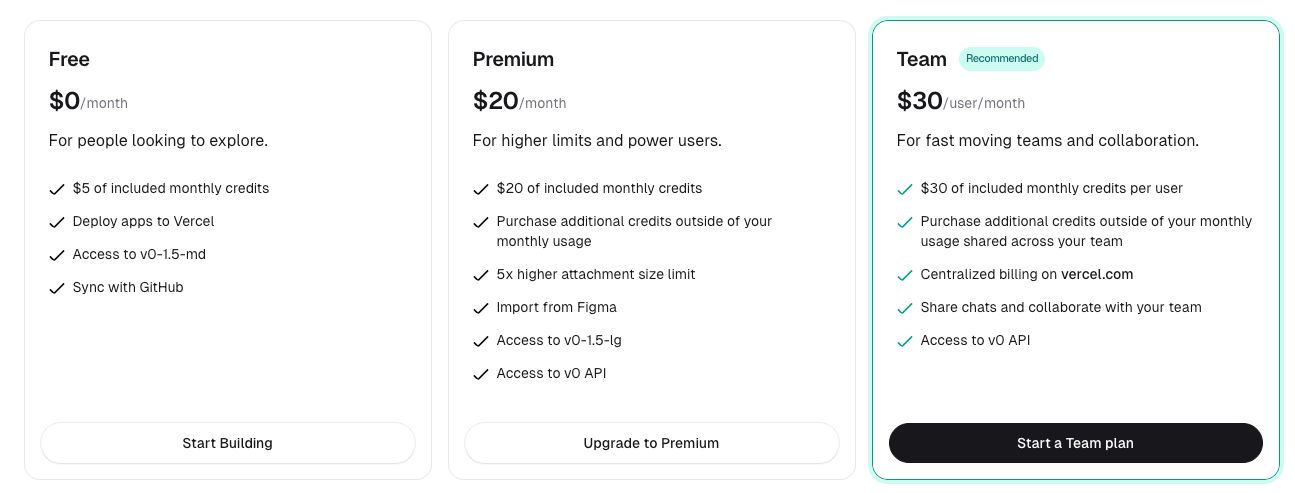
Vercel’s v0 reveals a strategic use of AI tooling to reinforce their broader platform ecosystem. Their credit-based pricing model aligns costs with actual token consumption while driving adoption of their core infrastructure.
v0 operates on a credit system where users receive monthly credit allowances: Free ($5), Premium ($20), Team ($30/user), and Enterprise (custom). Credits are consumed based on actual token usage across different model tiers, with v0-1.5-lg costing $7.50 per million input tokens and $37.50 per million output tokens, while smaller models like v0-1.5-sm cost significantly less at $0.50/$2.50 per million tokens.
The platform includes relevant context like chat history, source files, and Vercel-specific knowledge when generating responses, with this context counted as input tokens. Crucially, v0 heavily favors Next.js in its code generation (another Vercel product) creating a natural pathway from AI-assisted development to their hosting and deployment platform.
Tokenomics Takeaway: v0's transparent token-based pricing maps directly to user value perception while serving a larger strategic purpose. Users pay for actual compute consumption rather than abstract units, but more importantly, the tool generates Next.js applications that naturally deploy on Vercel's infrastructure. The AI tool becomes a customer acquisition engine for their core hosting business by making Vercel deployment the obvious next step after code generation.
Lovable: Transparent Task-Based Agent Pricing
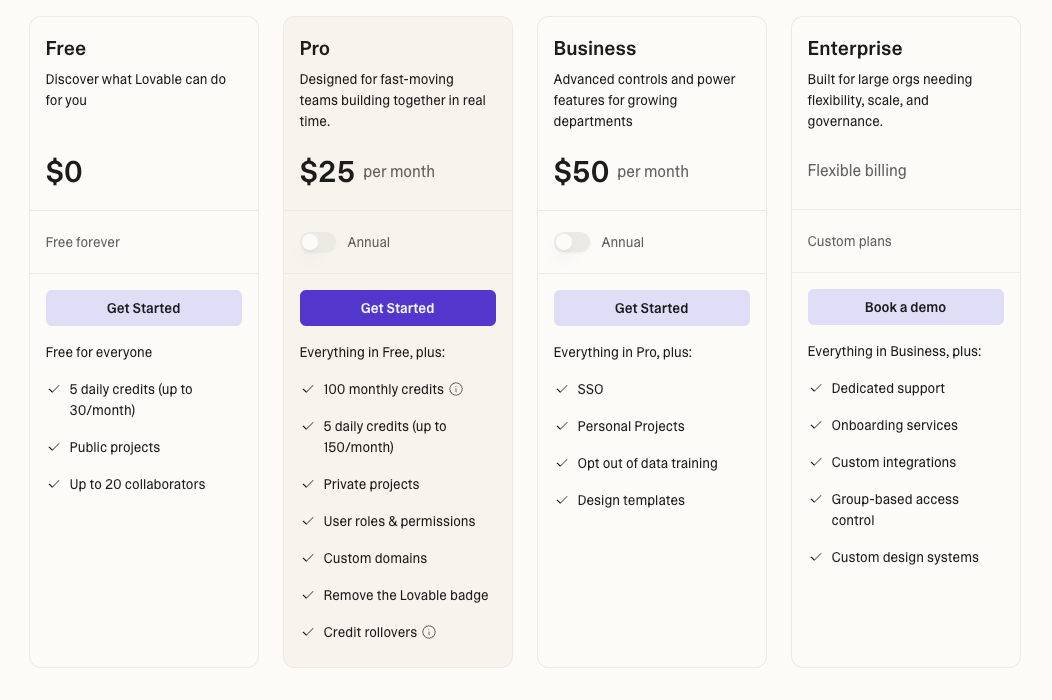
Lovable has evolved beyond simple message-based pricing to introduce a more sophisticated agent pricing model that charges based on the actual complexity and scope of work performed. While Default and Chat modes still cost 1 credit per message, their Agent Mode uses dynamic pricing that reflects the computational effort required for each task.
The Pro plan ($25/month) provides 100 monthly credits plus 5 daily credits (totaling up to 150 credits per month), with unused monthly credits rolling over. Agent Mode pricing varies significantly based on task complexity: removing a footer costs 0.90 credits, adding full authentication with sign-up and login costs 1.20 credits, while building a complete landing page with generated images runs 1.70 credits.
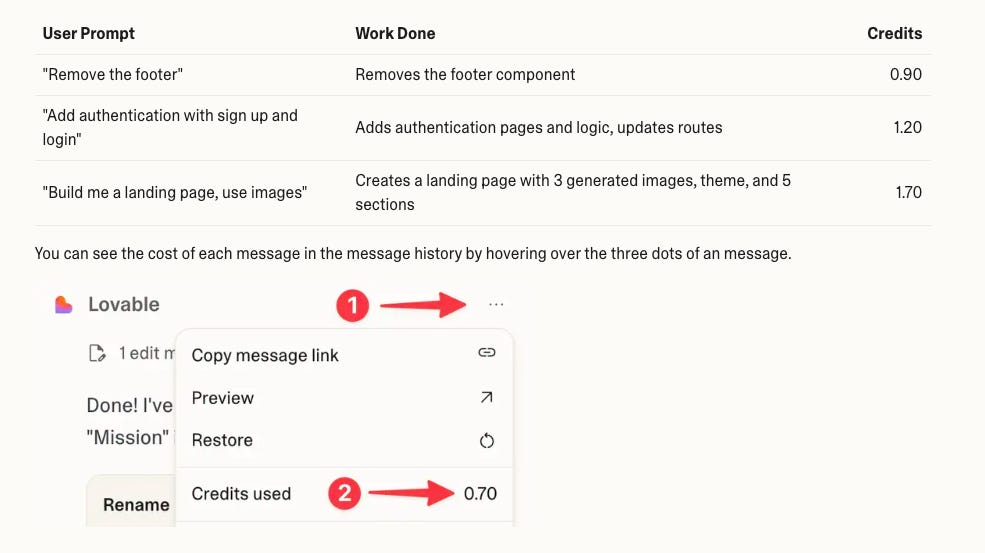
This is a fundamental shift from uniform pricing to outcome-based billing. Simple edits and removals cost less than a full credit, while complex multi-component builds cost more. Users can see the exact cost of each message by hovering over message options in their history.
Tokenomics Takeaway: Lovable's approach addresses one of the core problems in AI tool pricing: the massive variance in computational work between simple and complex requests. What sets them apart is the radical transparency: users can see the exact cost of each individual message by hovering over message options in their history. By moving to task-complexity pricing in Agent Mode with full cost visibility, they've created a model where users pay more fairly for what they actually get while understanding exactly what each interaction costs.
OpenAI Codex (non-API): The Subscription-Freebie (for now?)

Being still in early access, OpenAI's Codex is included with ChatGPT Pro ($200/month), Enterprise, Team, and Plus subscriptions, providing "generous access at no additional cost" during the initial rollout period, after which rate limits and on-demand pricing will apply.
Tokenomics Takeaway: Time will tell when they release pricing.
Bolt.new: Flat Fee, Token Ceilings
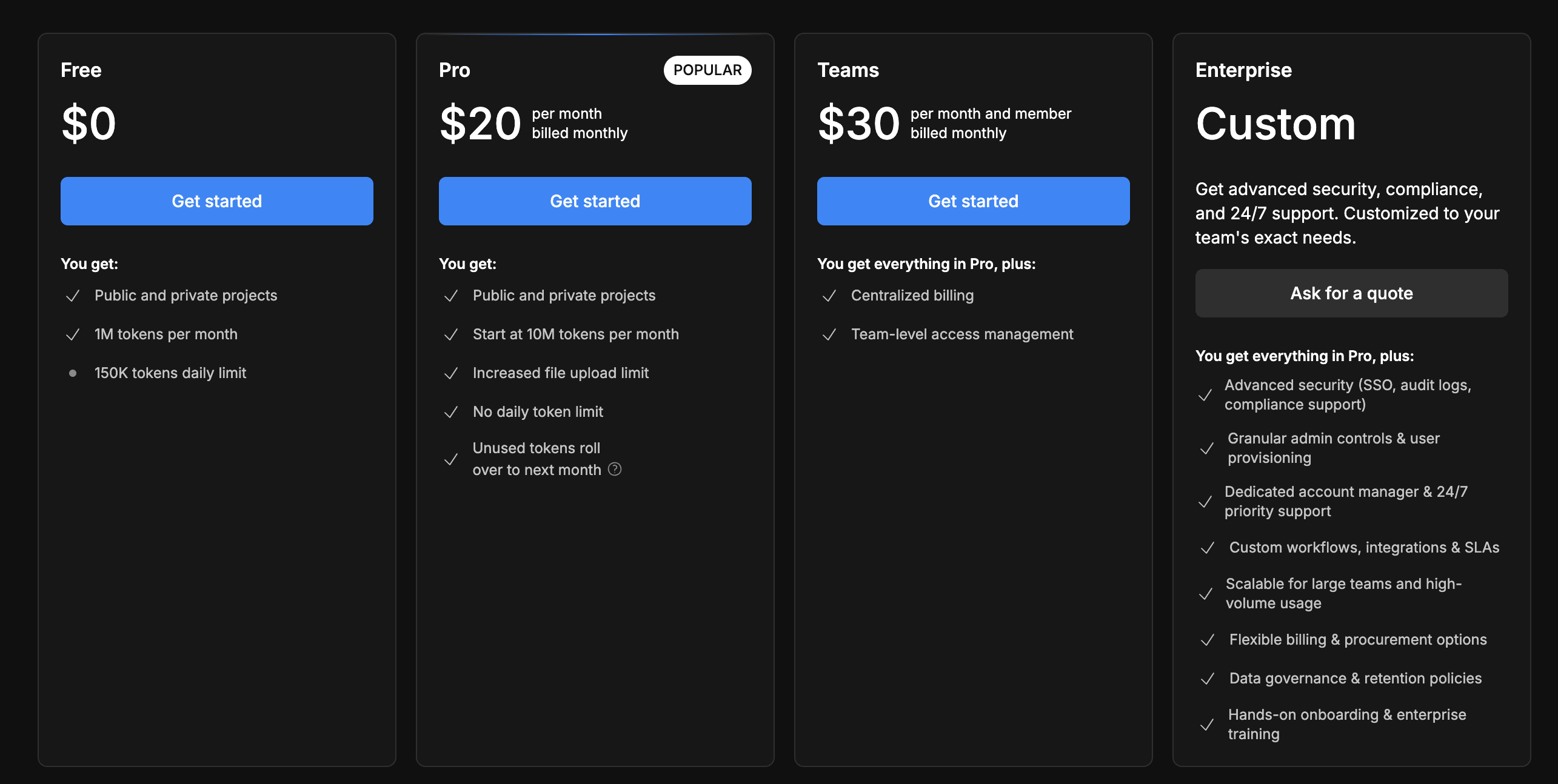
Bolt presents itself as the simple option: $0 to start, $20/month for Pro, and $30/month per user for Teams. But behind the clean UI is a usage model that centered around tokens.
The free plan comes with 1 million tokens per month and a 150K daily limit. Which is enough for basic usage, but you hit the daily cap almost immediately when trying to build anything with complexity. The Pro plan bumps you up to 10 million tokens per month, removes the daily cap, and allows unused tokens to roll over. The Teams tier adds admin features like centralized billing and access controls, but keeps the same usage base.
There’s no per-request or per-agent billing here, just token ceilings. And while “unlimited” isn’t part of the pitch, the framing still feels generous compared to some of the newer credit-based or task-metered models. That said, the token cap means power users (especially those experimenting with background agents or long context windows) will need to track usage, even on paid plans.
What sets Bolt apart is actually the integrated development environment. Unlike tools that operate as plugins or external agents, Bolt provides a complete IDE where you can code, preview, and deploy full-stack applications entirely in the browser. This also means that users can modify code without spending tokens (especially helpful in getting out of those pesky troubleshooting loops that can burn tokens).
Tokenomics Takeaway: Bolt’s pricing looks flat, but it’s grounded in hard token ceilings. It’s a middle ground between flat-rate simplicity and usage-based fairness making it more predictable than credit-based models, but still constrained. Bolt’s approach creates stronger user lock-in than standalone coding assistants, as switching costs include not just the AI tool but the entire development workflow. The token-based pricing works within this model because users are paying for platform access, not just AI interactions.
Replit: Effort-Based Pricing via “Checkpoints”

Replit’s pricing page has an interesting strategy, comparing the money you spend to money you recieve ($20/month for $25 worth of credits). Though, “credits” seems opaque since there isn’t an immediate way to calculate the value or output you’ll get from $25 worth of Replit credits. But diving deeper into their effort-based pricing blog, it’s actually quite interesting. Read it here.
Replit rolled out an effort-based pricing model in mid-2025 that charges users based on the actual complexity of each task, rather than by token or message count. The system uses “checkpoints” to measure work, so instead of every request costing the same, simpler edits (like renaming a variable) might cost a few cents, while more involved tasks (like building a new component) cost more.
Each checkpoint’s price is visible in the interface, and usage rolls up into a monthly credit allowance ($25 on the Core plan, $40 per user on Teams) with the goal to make pricing more aligned with actual work done.
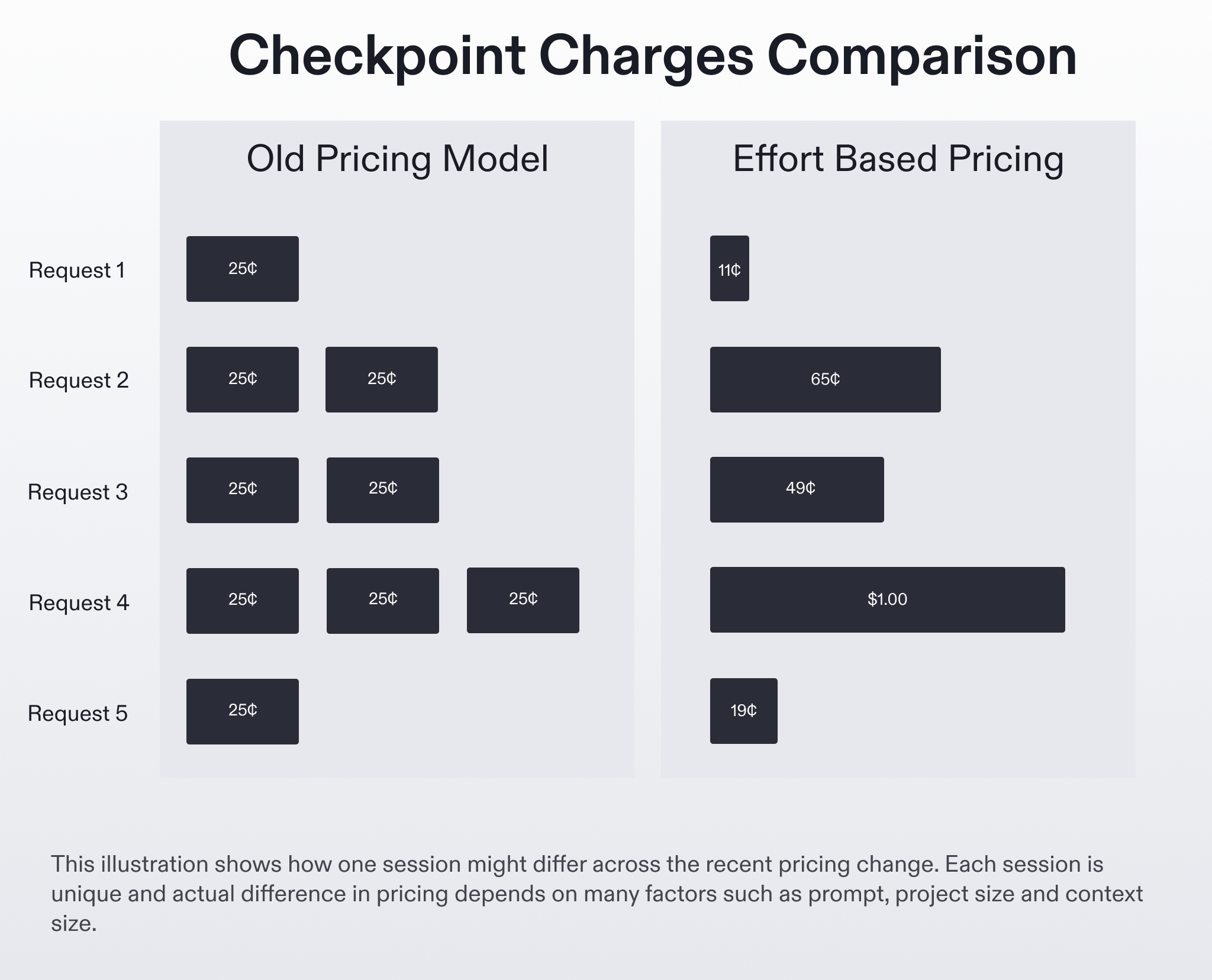
Tokenomics Takeaway: Replit’s effort-based pricing is an attempt at turning usage-based into something closer to “customer value”. But since it’s hard to quantify value, I think “effort” is an apt name. It seems pretty similar to Lovable’s agent and complexity-based pricing, but there’s something there in calling it “effort-based”.
What This All Means for Founders
The evolution of developer tool pricing reveals several critical lessons:
Flat-rate pricing isn't inherently wrong — especially in the early days, it’s still a great way to win when introducing new behaviors. Your first job isn't to maximize revenue; it's to build habits. Both Cursor and GitHub Copilot succeeded initially with flat pricing.
Transparent usage dashboards aren't optional in the AI era. Customers need to (and will soon demand to) understand their consumption patterns before they hit surprise bills. The tools with the smoothest transitions all invested heavily in usage visibility.
Hybrid models (base + credits) give predictability without unlimited exposure. Having predictable costs will still make the deal more tenable for enterprise procurement teams. Many AI-native tools are converging on this approach, though they implement it differently.
Abstraction can solve complexity, but requires careful design. Units should map meaningfully to both real costs and user value perception.
The Next Potential Tipping Point: Agent Swarms
The next wave of disruption won't be from individuals building faster; it'll be from code writing itself in swarms. Agentic development tools are showing us what happens when you give five agents the ability to coordinate, refactor, and reason about an entire codebase simultaneously.
Swarm-based workflows introduce powerful new capabilities like full-codebase refactoring and speculative scaffolding, but they also risk blowing up cost models entirely. What used to be a single developer calling the model a few times per day becomes 5–10 agents each calling different tools, running context windows in parallel, and looping over 1,000+ documents to complete a task. With no human in the loop, token consumption may become unpredictable and uncapped.
Adrian Cockcroft's Example on Swarms at Work
Developer tools are going through a pricing reset similar to its technological counterpart. As AI becomes more embedded, looping in the background, calling tools, writing code autonomously, flat fees and per-seat models start to break down. Each tool is handling it differently: Cursor moved from requests to tokens, Devin bundles compute into time-based units, and Bolt keeps things simple with monthly token caps. There’s no perfect answer yet, but one thing’s clear: pricing now has to reflect real compute costs, not just user count. And as multi-agent workflows become more common, those costs are only going to get harder to predict.